
在这篇文章中,我们简单介绍PEFT概念、PEFT方法,和在Huggingface中的实现方式。
What is PEFT and why?
PEFT(Parameter Efficient FineTuning),概念源于模型微调。之前的 Full-Finetuning 一般指的是对下游任务加入一些新数据,再训练几个 Epochs。
Problem:
- 参数量大的时候 (>?B),Full-finetuning 耗时耗钱、而且模型太大有可能完全调整不动
- 灾难性遗忘,学了新知识忘了旧知识
Assumption:
- 模型在参数量上去之后,产生了某种意义上的通用智能(如推理能力)
Solution:
- 是不是通过调整一部分参数,或是增加一部分参数就可以在很多新任务上取得不错的效果?引出了高效参数微调,针对LLM 调整/添加 较小的一部分参数,大约是
0.01%-10%,到达和全参数微调后的模型 compatible 的效果。
How?PEFT有哪些方法?
| Name | Paper | Time |
|---|---|---|
| Adapter | Parameter-Efficient Transfer Learning for NLP | 2019-02 |
| PrefixTuning | Prefix-Tuning: Optimizing Continuous Prompts for Generation | 2021-01 |
| PromptTuning | The Power of Scale for Parameter-Efficient Prompt Tuning | 2021-09 |
| LoRA | LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS | 2021-10 |
| BitFit | BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models | 2022-09 |
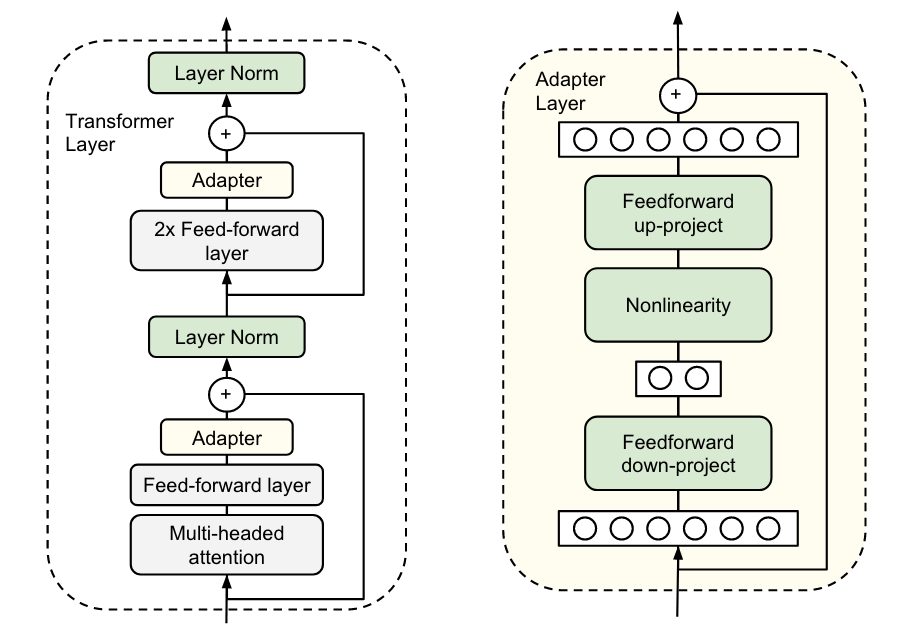
Adapters
Bottleneck Adapter: Parameter-Efficient Transfer Learning for NLP
- Bottleneck arch (control the #params)
- Skip-connection (initialize proj to 0 makes identity)
![adapter]()
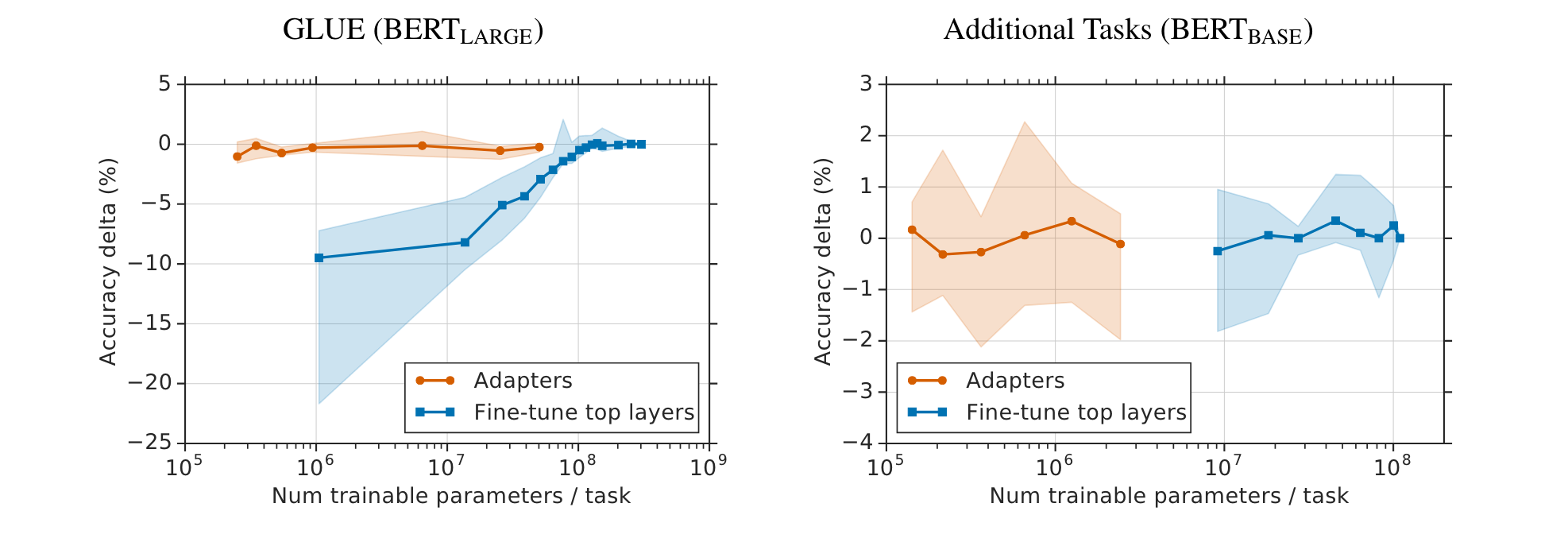
Exps on text-classification shows adapter achieves compatiable results to full-finetuning or varaible finetuning. (lower 0.4%):

Adapter Family
| name | idea | paper-url |
|---|---|---|
| AdapterLowRank | 把Adapter中的线性层换成两个low-rank矩阵 | COMPACTER: Efficient Low-Rank Hypercomplex Adapter Layers NeurIPS 2021 |
| AdapterDrop | 不要前几层Transformer里的adapter | AdapterDrop: On the Efficiency of Adapters in Transformers 2021.emnlp |
| AdapterFusion | 不同任务的Adapter 融合 | https://aclanthology.org/2021.eacl-main.39.pdf 2021.eacl |
Prefix-Tuning
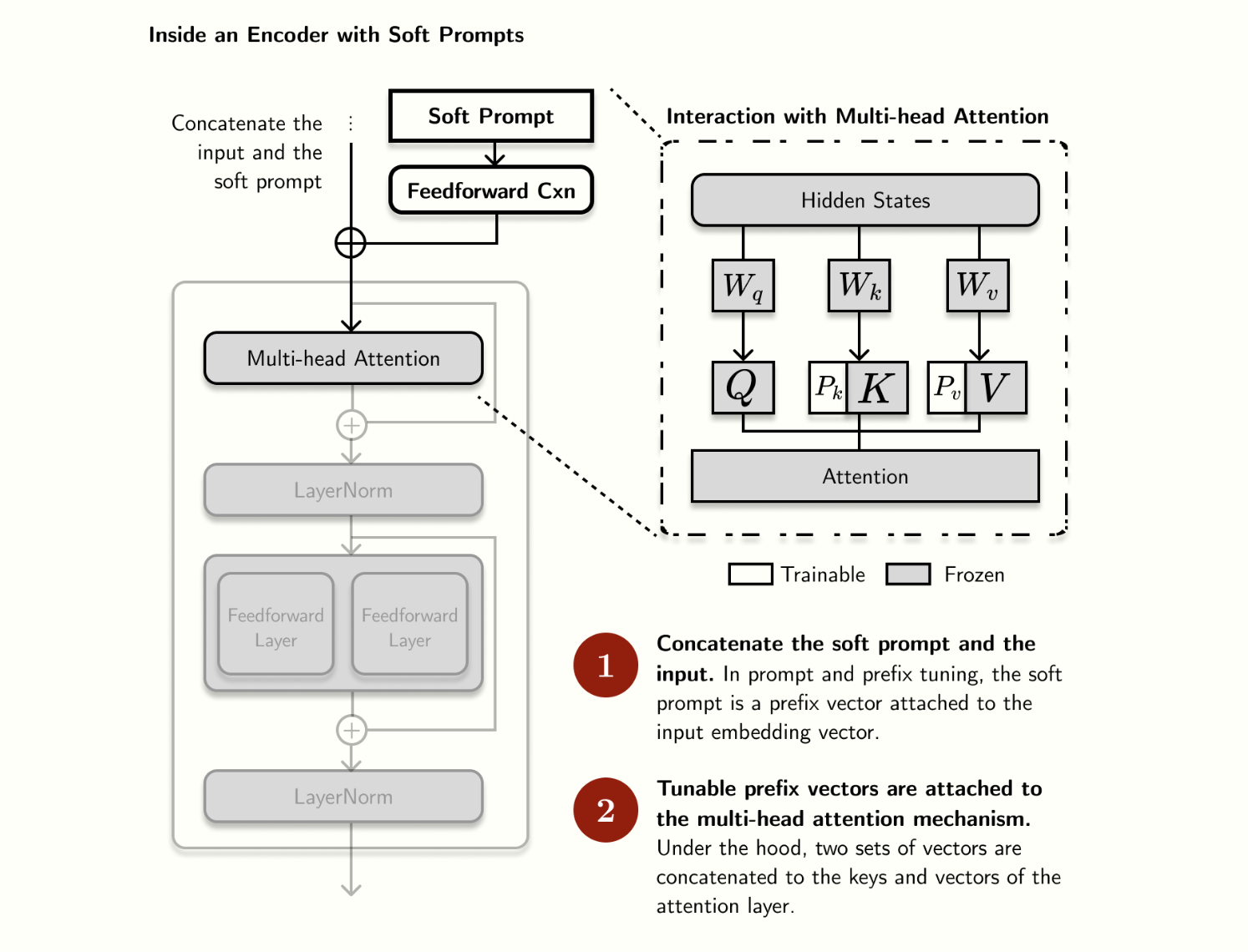 这个思想的实现方式比较 Tricky,Code 如下:
这个思想的实现方式比较 Tricky,Code 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class PrefixEncoder(torch.nn.Module):
def __init__(self, config):
super().__init__()
self.prefix_projection = config.prefix_projection
token_dim = config.token_dim
num_layers = config.num_layers
encoder_hidden_size = config.encoder_hidden_size
num_virtual_tokens = config.num_virtual_tokens
if self.prefix_projection and not config.inference_mode:
# Use a two-layer MLP to encode the prefix
self.embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
self.transform = torch.nn.Sequential(
torch.nn.Linear(token_dim, encoder_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
)
else:
self.embedding = torch.nn.Embedding(num_virtual_tokens, num_layers * 2 * token_dim)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.transform(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values
我们可以看到多了线性层 num_layers * 2 * token_dim , 就是指每层注意层都会加一些东西,那为什么 还要乘 2 呢? 因为会分别变成 Prefix-key 和 Prefix-value。和原来模型的 Query 交互。这里的实现用到了 past_key_values 的机制,past_key_values 之前是用来做加快decode 过程做的缓存,可以存住过去的embedding生成的key-values,从而避免重复计算。这里刚好用了这个机制作为 Prefix,具体实现还是比较复杂,不是那么好理解,会涉及到 Transformer 库的源码。
Exps on table-to-text generation & summarization. 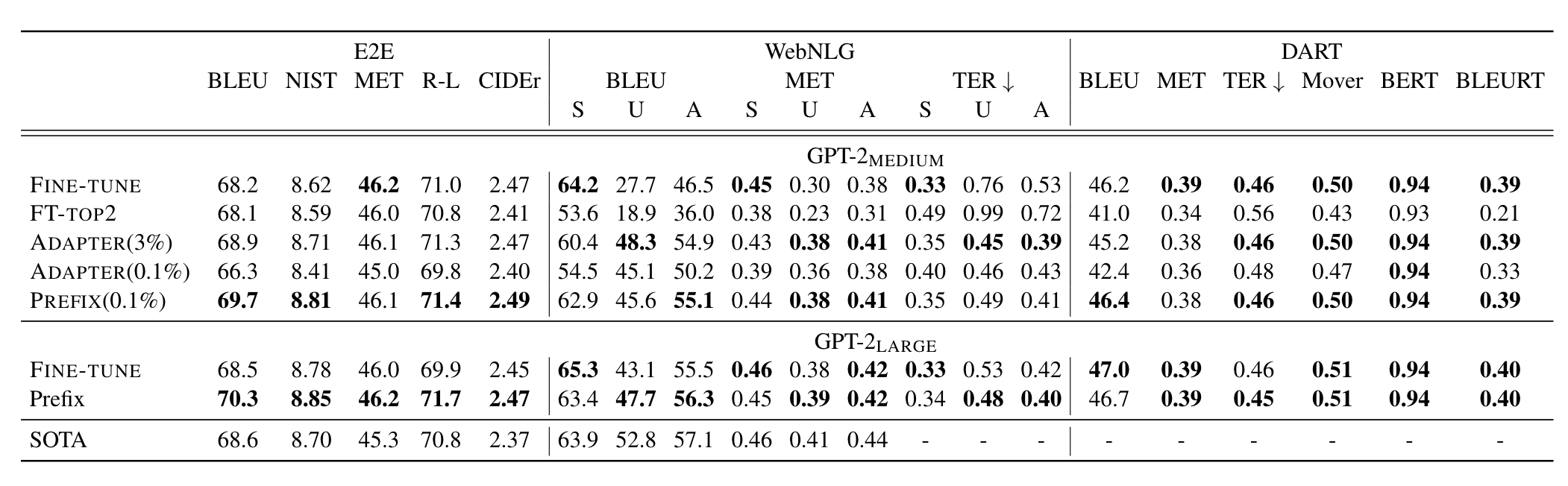 在小样本上展现出了非常好的性能。
在小样本上展现出了非常好的性能。 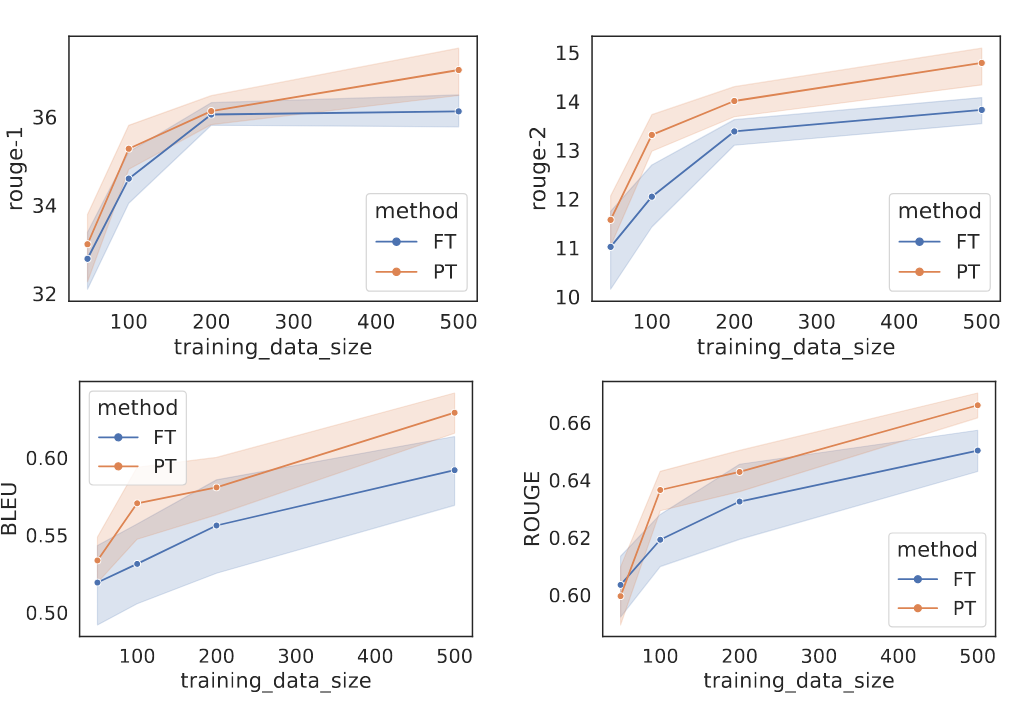
P-tuning
Paper: GPT Understands, Too 和接下来的 Prompt-Tuning 非常类似,它的 Assumption 是在于学习提示 Soft Prompt 模版,使用LSTM(提示有联系)。
Prompt Tuning
Paper: The Power of Scale for Parameter-Efficient Prompt Tuning Idea: 大道至简,不要整乱七八糟的,就在输入前增加 Input Tokens,再增加一个 Embedding 层。得出结论:规模越大效果越好,scale is all you need.
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
class PromptEmbedding(torch.nn.Module):
"""
The model to encode virtual tokens into prompt embeddings.
Input Shape: (`batch_size`, `total_virtual_tokens`)
Output Shape: (`batch_size`, `total_virtual_tokens`, `token_dim`)
"""
def __init__(self, config, word_embeddings):
super().__init__()
total_virtual_tokens = config.num_virtual_tokens * config.num_transformer_submodules
# 新增的 Prompt 的Embedding 层
self.embedding = torch.nn.Embedding(total_virtual_tokens, config.token_dim)
if config.prompt_tuning_init == PromptTuningInit.TEXT:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(config.tokenizer_name_or_path)
init_text = config.prompt_tuning_init_text
init_token_ids = tokenizer(init_text)["input_ids"]
# Trim or iterate until num_text_tokens matches total_virtual_tokens
num_text_tokens = len(init_token_ids)
if num_text_tokens > total_virtual_tokens:
init_token_ids = init_token_ids[:total_virtual_tokens]
elif num_text_tokens < total_virtual_tokens:
num_reps = math.ceil(total_virtual_tokens / num_text_tokens)
init_token_ids = init_token_ids * num_reps
init_token_ids = init_token_ids[:total_virtual_tokens]
# 这里复制了原有的 Embedding 层参数
word_embedding_weights = word_embeddings(torch.LongTensor(init_token_ids)).detach().clone()
word_embedding_weights = word_embedding_weights.to(torch.float32)
self.embedding.weight = torch.nn.Parameter(word_embedding_weights)
def forward(self, indices):
# Just get embeddings
prompt_embeddings = self.embedding(indices)
return prompt_embeddings
Results:模型越大效果越接近,PromptTuning和ModelTuning没区别
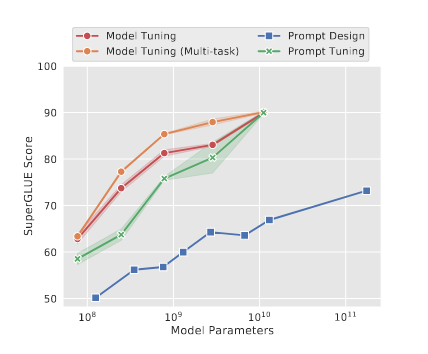
Ablations: 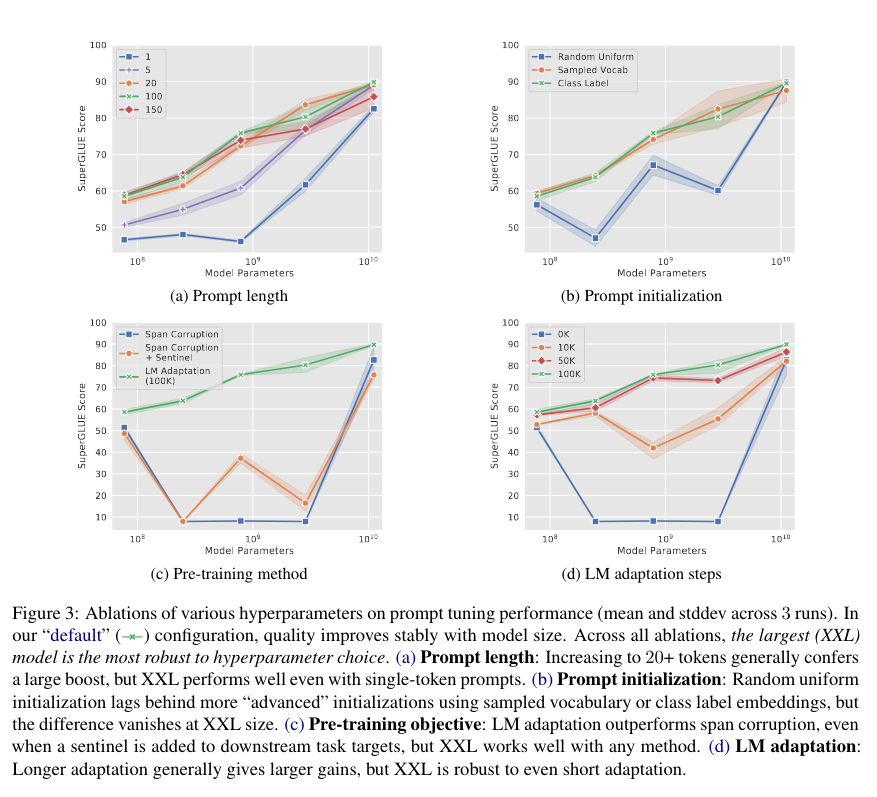
- a 不同的 #prompt tokens 的影响,模型参数不够影响大,模型参数大没啥影响都很好
- b 初始化的作用
- c 不同初始化预训练模型初始化(T5模型),没训练 / 加个Prompt Sentinel / 用新的Sentinel训练一下PLM
- d 训练步骤
全都反应出 Scale is all you need, 同时这个趋势还是直线
why work with such simple methods?
- BP 梯度回传还是得传到最前面
Bitfit
只调节 Bias Term,结果也相当不错

LoRA
Paper: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
已有方案的问题:
- Adapters引入额外的推理延迟 (由于增加了模型层数)
- Prefix-Tuning难于训练,且预留给prompt的序列挤占了下游任务的输入序列空间,影响模型性能
基于一个Assumption: 虽然模型的参数很多,但模型的能力主要依赖低秩维度的内容(low intrinsic dimension)。 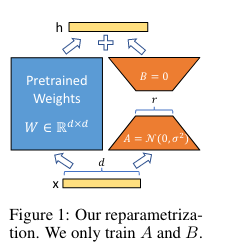
在原始PLM旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank 。训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。思想有点类似于残差连接。
- 训练效果好 & 稳定
- 比 Adapter 快
Others…
PEFT lib
- 先进入 get_peft_model,在里面配置了一些 config, 然后进入 Warp 模块 MODEL_TYPE_TO_PEFT_MODEL_MAPPING,把模型从任务层面分开,我们进入 Seq2Seq 这部分
- PeftModelForSeq2SeqLM 继承了 PeftModel,先PeftModel 初始化
如何新增自己的 PEFT 模块?
我想设计一个自己 PEFT 模块,该如何实现呢?
- 在
peft/tuners目录中设计好自己的模块,e.g.graph_tuning.py peft/tuners/__init__.py加入自己设计的 PEFT classpeft/__init__.py加入自己设计的 PEFT classpeft/mapping.py中 import 自己设计的 class & MAPPING 中加入peft/utils/config.py
Comments powered by Disqus.